強化學習

從模仿到自己犯錯:Google 如何用一個模型拿下數學奧林匹亞金牌
Google DeepMind 新加坡團隊負責人 Yi Tay 分享 Gemini 拿下國際數學奧林匹亞金牌的幕後故事。他們放棄了原本表現不錯的專用系統,賭上一切用通用模型挑戰,背後是一個關於 AI …

前 OpenAI 研究員:AGI 還缺兩塊拼圖,2026-2029 年可能達成
Jerry Tworek 主導了 OpenAI 的推理模型開發,親眼見證 Q-Star 第一次展現能力的時刻。他認為目前的模型離 AGI 還有距離,關鍵缺口是架構創新和持續學習。他也分享了對研究文化的 …

翁家翌:OpenAI 每一個模型背後的那個「賣鏟子的人」
從小學奧數、清華開源作業、天授框架、退學 online,到成為 GPT 系列核心貢獻者——翁家翌的故事是一個關於「資訊平權」與「投資未來」的旅程。但這個熱愛開源的工程師,如何自處於一個閉源的公司?
「每家 Infra 都有 bug,誰修得多誰就贏」—— OpenAI 核心工程師談 AI 競賽的真正戰場
OpenAI 核心工程師翁家翌在訪談中揭示 AI 競賽的殘酷真相:決定勝負的不是演算法創新,而是 Infra 的 bug 數量和迭代速度。這個觀點徹底顛覆了學術界對 AI 研究的想像。

當 AI 設計出「甜甜圈形狀」的晶片:AlphaChip 如何用強化學習創造超人類表現
Google AlphaChip 團隊用強化學習讓 AI 自主學習晶片佈局,結果 AI 設計出人類從未嘗試的彎曲形狀,效能反而更好。這個故事揭示了 AI 突破人類認知框架的潛力,以及導入傳統產業的真實 …

Karpathy:「強化學習很糟糕,只是之前的方法更糟」
Andrej Karpathy 對強化學習提出尖銳批評:我們正在「用吸管吸取監督訊號」。人類根本不是這樣學習的。但目前沒有更好的方法,所以我們只能繼續用這個「很糟糕」的工具。

訓練 AI 代理的四個不能妥協——OpenAI 的 Agent RFT 實戰指南
OpenAI 分享使用 Agent RFT 訓練 AI 代理的四大成功原則:任務要明確可評分、訓練資料要像生產環境、讓模型有探索空間、以及獎勵函數不能被鑽漏洞。這些原則來自與 …
OpenAI 讓 AI 在訓練時操作真實世界——Agent RFT 是什麼?
OpenAI 推出 Agent RFT,首次讓模型在訓練過程中與外部世界互動。這項技術允許 AI 代理在訓練時呼叫真實的工具端點,並透過自訂獎勵函數學習最佳行為模式。對於打造企業級 AI 代理的開發者 …
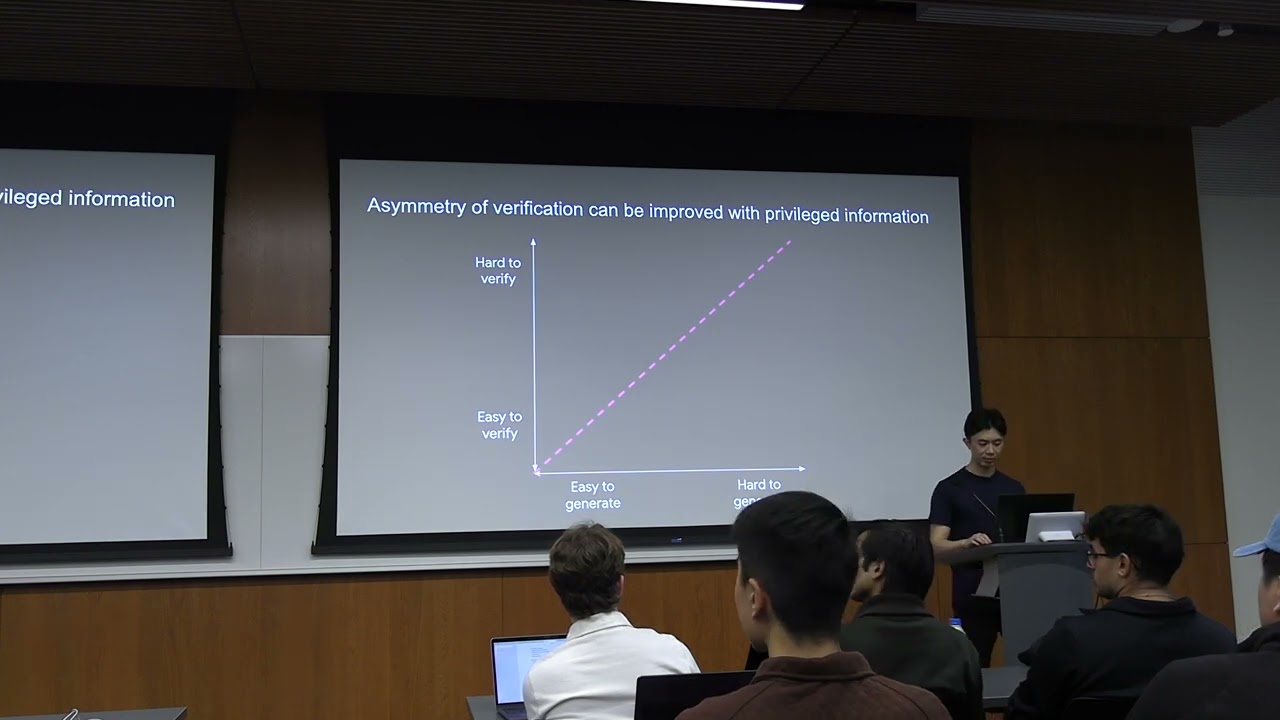
驗證者法則:為什麼容易打分數的任務,會最先被 AI 征服
OpenAI o1 共同創作者 Jason Wei 提出「驗證者法則」:AI 訓練能力與任務可驗證性成正比。這個框架解釋了為什麼 AI 在某些領域進步神速,在某些領域卻停滯不前,也指出了下一波突破會發 …
安德魯・巴托 Andrew Barto
一句話認識他 Andrew Barto 是強化學習的共同創始人,與學生 Richard Sutton 一同為 AI 建立了「從試錯中學習」的理論基礎。 為什麼重要? 當你問 ChatGPT 一個問題, …
德米斯・哈薩比斯 Demis Hassabis
一句話認識他 Demis Hassabis 創立了 DeepMind,開發了打敗圍棋世界冠軍的 AlphaGo,以及獲得諾貝爾化學獎的 AlphaFold——他正在用 AI 改變人類認識世界的方式。 …
理察·薩頓
理察·薩頓(Richard Sutton)是「強化學習之父」,2024 年圖靈獎得主。他定義了強化學習的理論框架和核心演算法,他的著作《強化學習導論》培養了整整一代研究者。沒有他的工作,就沒有 …